A Special Day for Lila and One Very Special Family
Today at CSE, we are celebrating a truly meaningful moment in a surrogacy journey—our surrogate mother, Lila, has safely delivered a beautiful baby girl.
Behind this joyful birth is a family who has waited for many years to become parents. After multiple fertility treatments and a long journey through infertility, their dream has finally come true.
This is more than a birth. It is the end of a long wait, and the beginning of a new family story.
A Journey Built on Hope, Trust, and Strength
Lila’s surrogacy journey began with a simple but powerful intention: to help another family experience the joy of parenthood.
From the very beginning, she committed herself fully to the process—completing medical screening, preparing for embryo transfer, and carefully following every stage of prenatal care under medical supervision.
Throughout the pregnancy, Lila remained strong, healthy, and dedicated, while also maintaining close communication with the intended parents who were eagerly following every milestone of their baby girl’s development.
Each ultrasound, each appointment, and each update brought them closer to the moment they had been waiting for years.
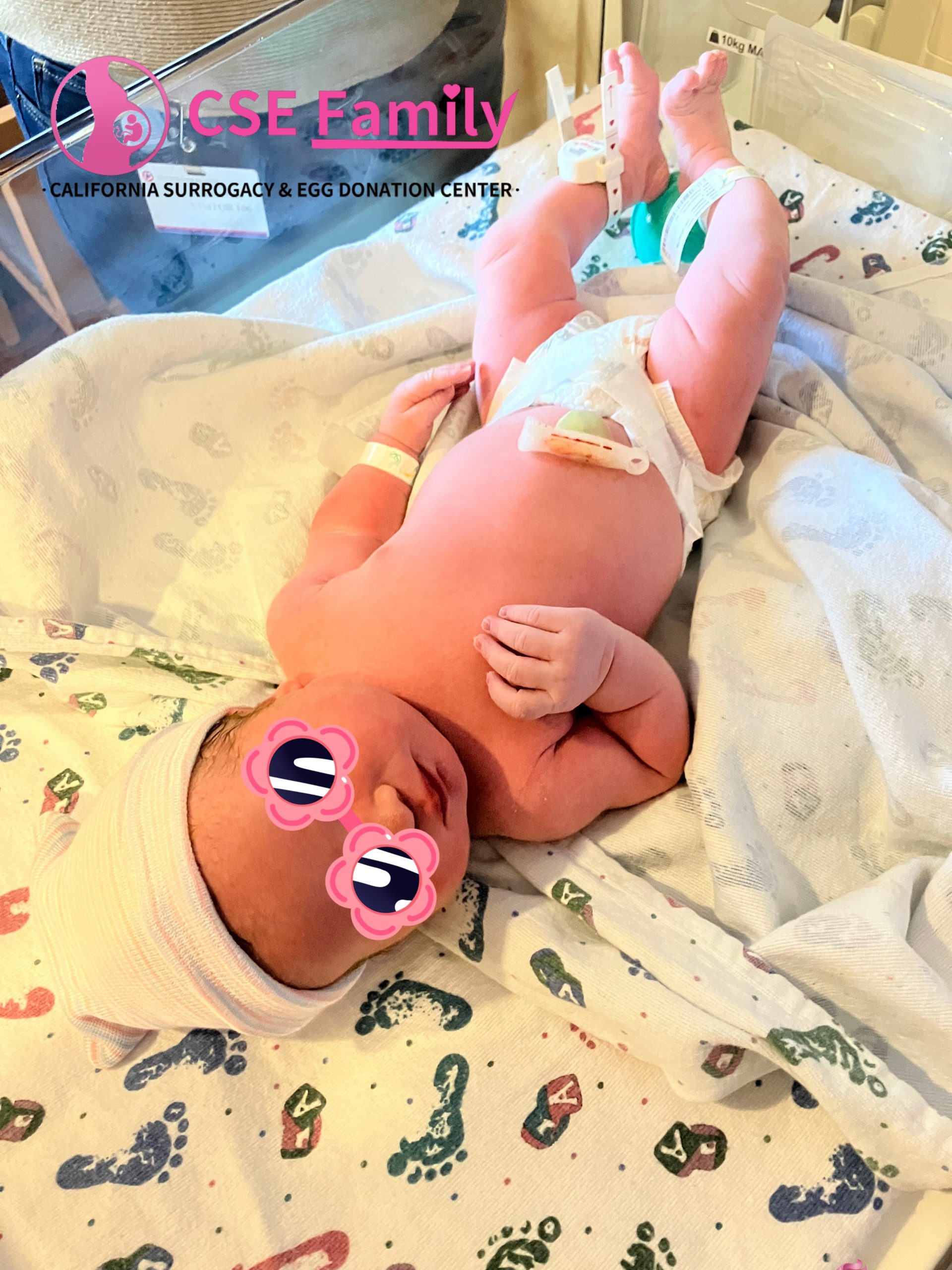
A Baby Girl Long Awaited by Her Parents
For the intended parents, this baby girl represents something deeply emotional.
After years of infertility struggles, unsuccessful attempts, and moments of uncertainty, they had nearly reached the edge of giving up hope.
But surrogacy gave them a new path forward—and Lila became the person who helped carry their greatest dream.
Today, they finally get to hold their daughter in their arms for the very first time.
A moment once imagined for years is now real.
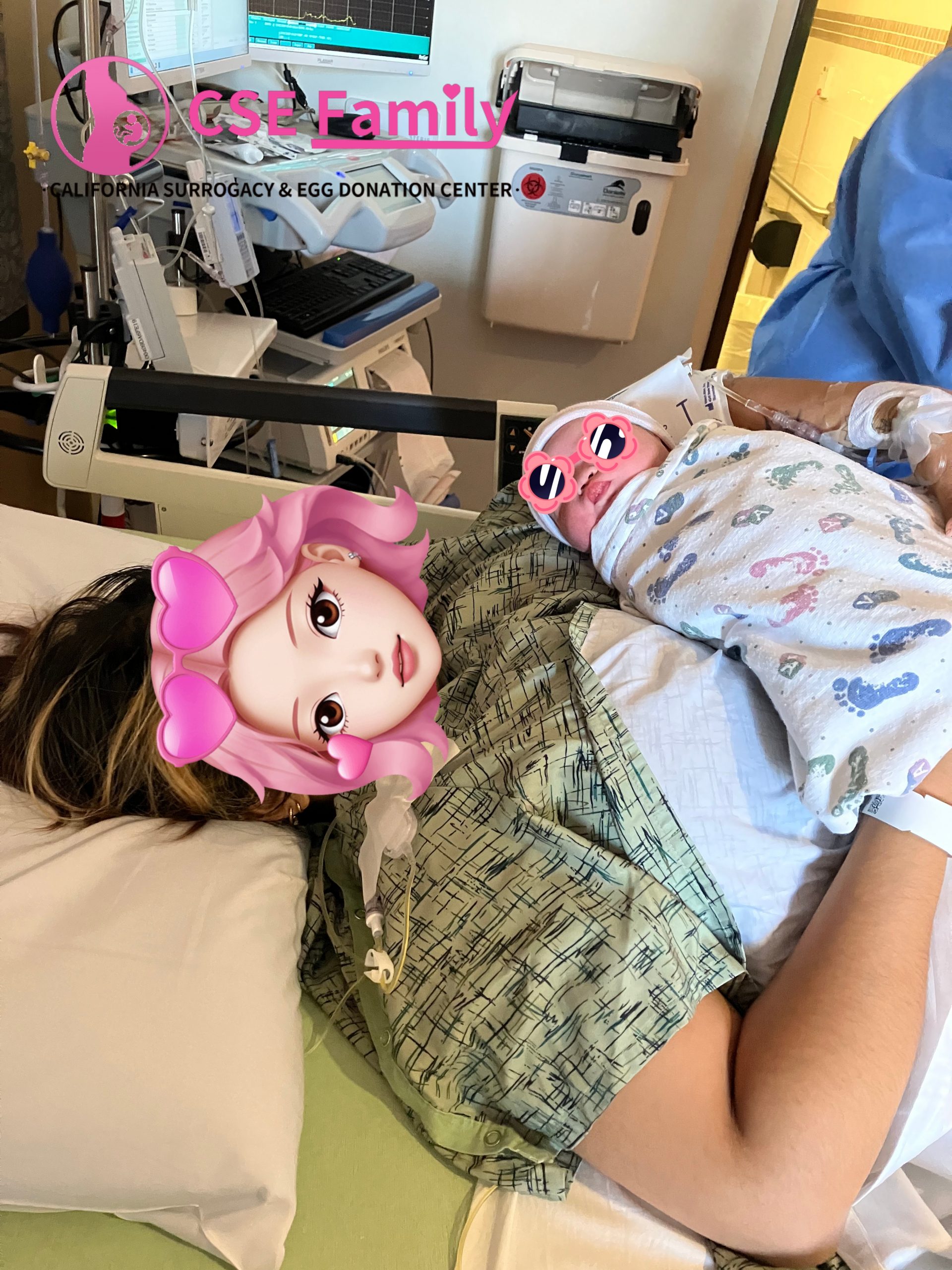
The Moment of Birth: A Life-Changing Experience
The delivery day was filled with emotion, gratitude, and overwhelming joy.
As the baby girl was born, the room was filled with tears of happiness from everyone involved—the medical team, the surrogate, and most importantly, the new parents.
For Lila, it was the completion of an incredible journey—one that required strength, compassion, and deep commitment.
For the intended parents, it was the moment their family finally became complete.
A child was born. A mother and father were born. A family was created.
Honoring Lila’s Strength and Compassion
Lila’s journey reflects what surrogacy truly means at CSE.
It is not only about carrying a pregnancy—it is about carrying hope, trust, and love for another family.
Her dedication made it possible for a couple who once struggled with infertility to finally experience the joy of becoming parents.
She is:
- A giver of hope
- A builder of families
- A symbol of compassion and strength
Her impact will always be remembered as part of this family’s beginning.
A Message of Gratitude from CSE
At CSE, we are deeply grateful to Lila for her extraordinary kindness and commitment throughout this journey.
And we celebrate the intended parents, who never gave up on their dream of having a child.
Today, a baby girl has been welcomed into the world through surrogacy, and a family that once waited for years is finally complete.
Thank you, Lila, for helping make this miracle possible.


{kind=link}
{kind=link}
{kind=link}